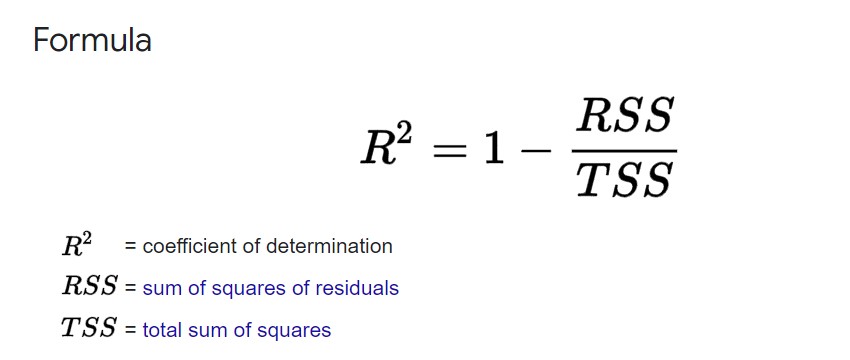Terms
– Bernoulli Distribution
2 Steps
– 1: Define a linear model
– 2: Define a link function
A linear model
\(\eta_i = \beta_o + \beta_1*X_i + ...\)
Note: \(\eta_i\) is some response of our linear model
Next steps
– Preform a transformation to our response variable so it has the appropriate range of values
– “Link” our linear model to the paramater of the outcome distribution
– \(y_i\) ~ Bern(p)
Generalized linear model
- Next, we need a link function that relates the linear model to the parameter of the outcome distribution i.e. transform the linear model to have an appropriate range
Logit Link Function
The logit link function is defined as follows:
![]()
\(\eta_i\) = \(log (\frac{p}{1-p})\)
– Note: log is in reference to natural log
Logit Link function
– A logit link function transforms the probabilities of the levels of a categorical response variable to a continuous scale that is unbounded
– Note: log is in reference to natural log
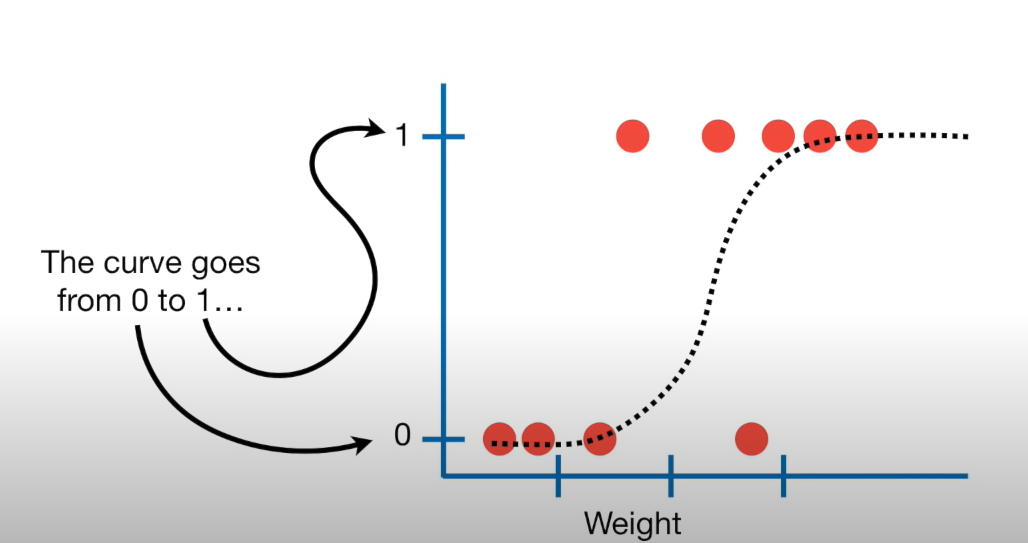
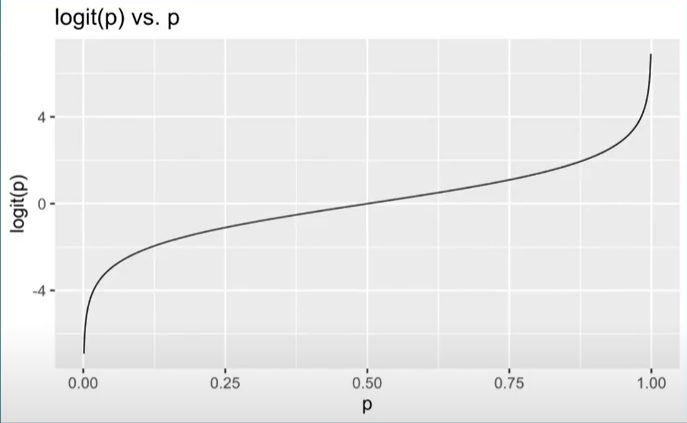
What’s this look like
Takes a [0,1] probability and maps it to log odds (-\(\infty\) to \(\infty\).)
![]()
Almost….
This isn’t exactly what we need though…..
Will help us get to our goal
So we have a generalized linear model (GLM)
\(logit(p_i)\) = \(\widehat{\beta_o} +\widehat{\beta}_1X1_i + ....\)
logit(p) is also known as the log-odds
logit(p) = \(log(\frac{p}{1-p})\)
\(log(\frac{p}{1-p})\) = \(\widehat{\beta_o} +\widehat{\beta}_1X1 + ....\)
One final fix
– Recall, the goal is to take values between -\(\infty\) and \(\infty\) and map them to probabilities. We need the opposite of the link function… or the inverse
– How do we take the inverse of a natural log?
- Taking the inverse of the logit function will map arbitrary real values back to the range [0, 1]
So
We need to take the inverse of the logit function
- \[log(\frac{p}{1-p}) = \widehat{\beta_o} +\widehat{\beta}_1X1 + ....\]