Joins + Tidy Data
Day 5
Duke University
STA 199 - Summer 2023
May 25th, 2023
Warm up - Joins
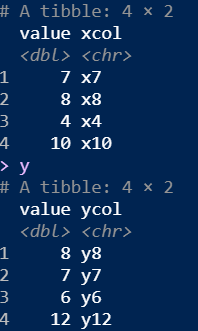
– left_join(x,y); right_join(x,y); full_join(x,y)
Function of the day

Function of the day
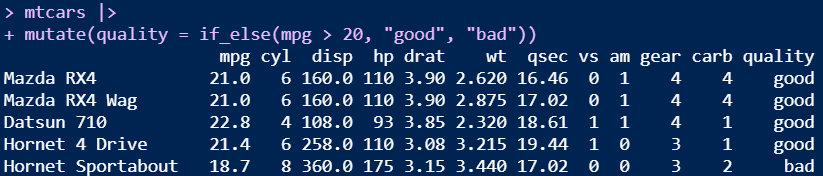
New column added
Bonus Function
fct_reorder
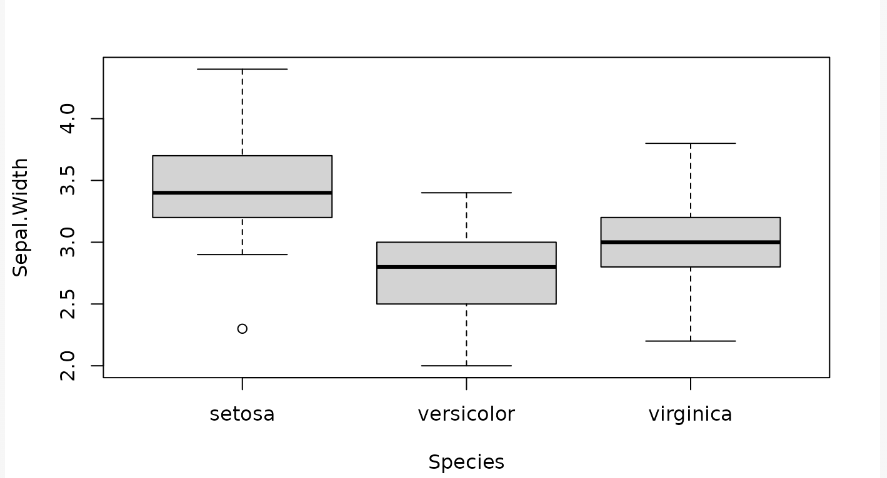
Function of the day (Bonus!)
iris |>
ggplot(
aes(x = fct_reorder(Species, Sepal.Width), y = Sepal.Width)
) +
geom_boxplot()

Data Format (Wide vs Long)
– Wide data contains values that do not repeat in the first column. Also called “unstacked”. Tabular format.
– Long data contains values that do repeat in the first column. Each row is a single observation of a particular group.
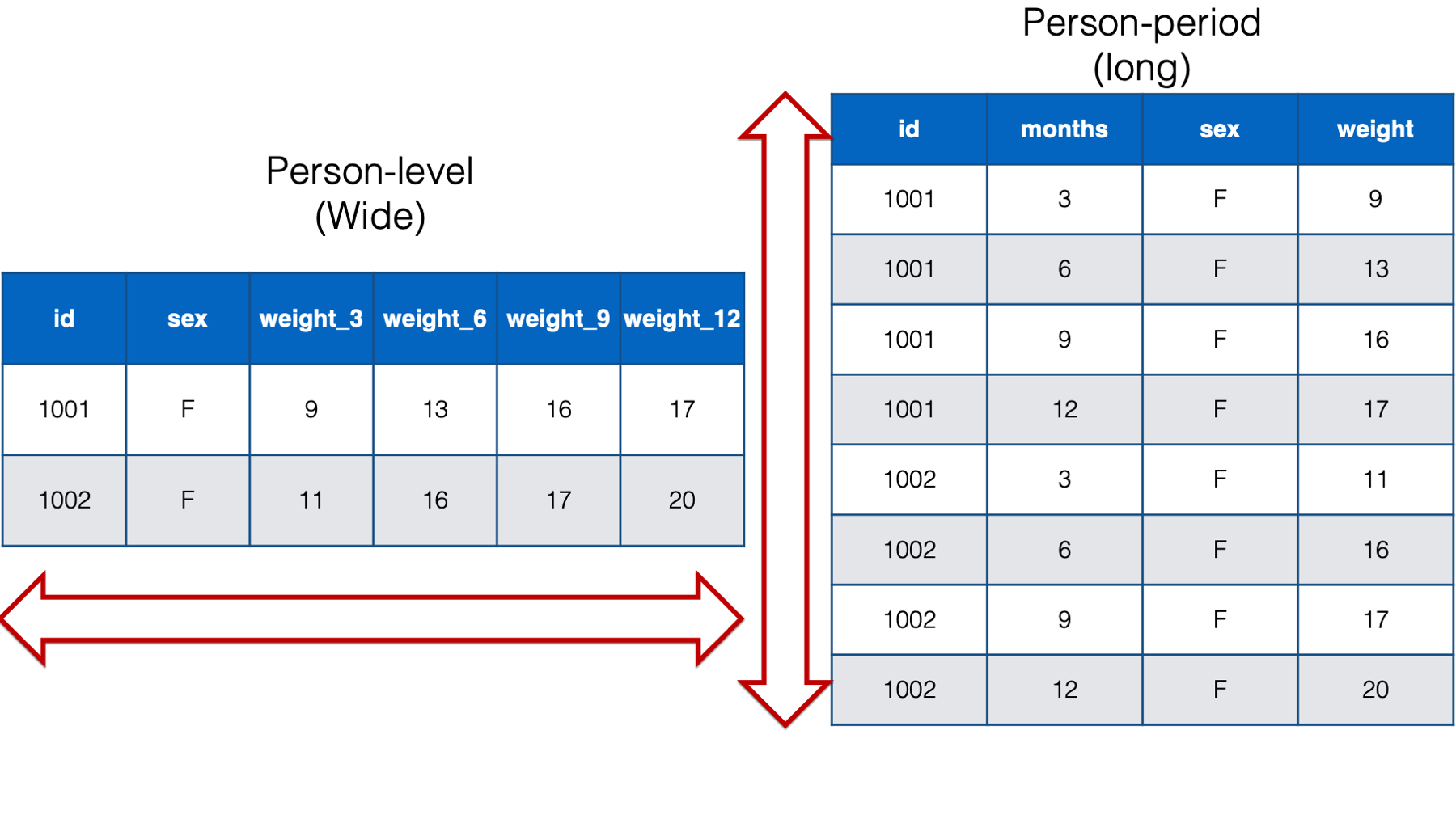
Data Format (Wide vs Long)
– Which have we typically used to create plots in this class?
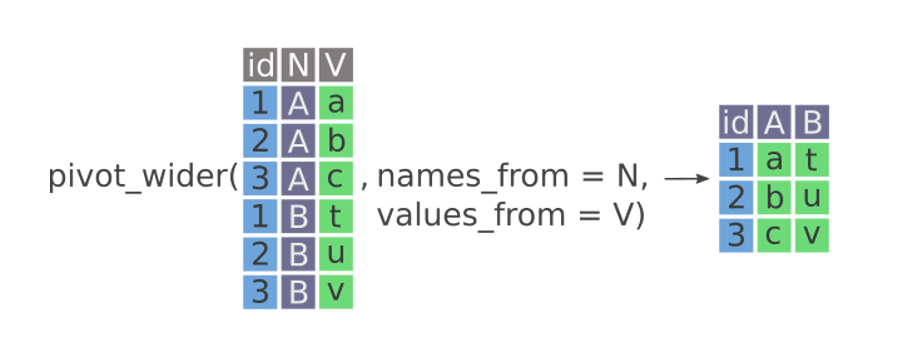
pivot_wider
– Making tables for quick comparison / display purposes
– names_to
– values_to
Pivot Motivation
Look at points by game

Recap of AE
There are many different types of joins. Think critically about your goal in order to decide which join you should use.
When pivoting longer, variable names that turn into values are characters by default. If you need them to be in another format, you need to explicitly make that transformation, which you can do so within the
pivot_longer()function.pivot_wider()which makes data sets wider by increasing columns and reducing rows.pivot_wider()has the opposite interface to pivot_longer(): we need to provide the existing columns that define the values (values_from) and the column name (names_from).